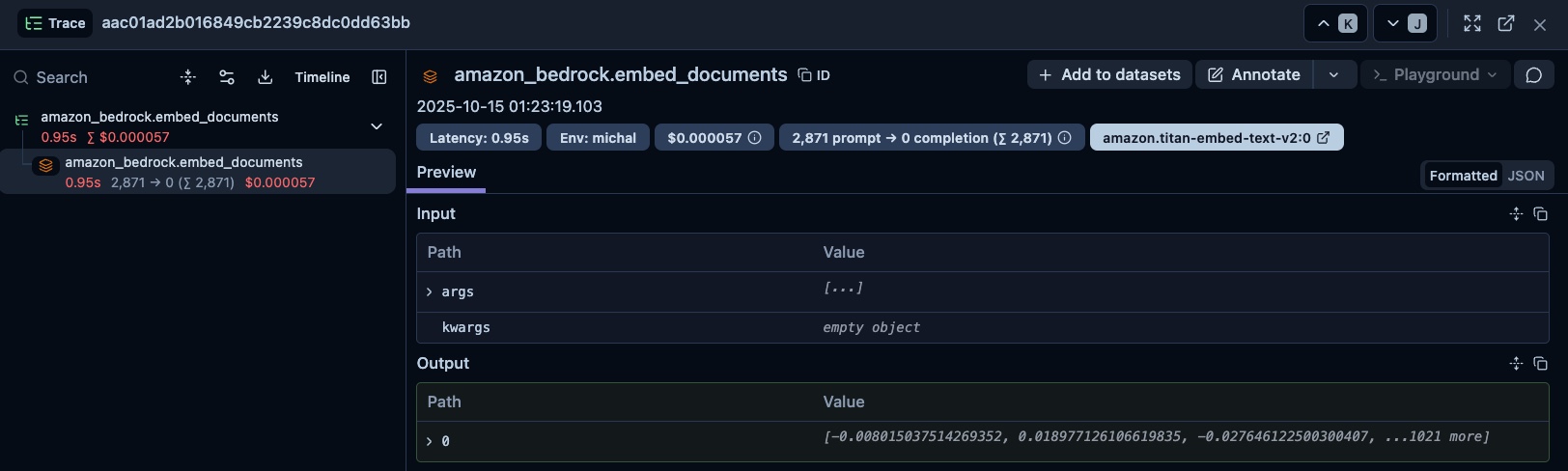
Tracing LangChain Embeddings with Langfuse
When working with LangChain and Langfuse, you’ll notice that while LLM calls are automatically traced via the CallbackHandler, embedding calls are not captured out of the box. Here’s a simple wrapper that adds full observability to any LangChain embeddings model.
The Problem
Langfuse’s LangChain integration uses callbacks, but LangChain’s embedding models don’t fire callbacks the same way chat models do. This means your embedding operations remain invisible in your traces.
The Solution
We wrap any LangChain embeddings model with a class that uses Langfuse’s @observe decorator:
import math
from typing import Optional
from langchain.embeddings.base import Embeddings
from langchain_core.runnables.config import run_in_executor
from langfuse import LangfuseEmbedding, get_client, observe
langfuse_client = get_client()
class LangfuseObservedEmbeddings(Embeddings):
"""Wraps an embedding model to trace calls with Langfuse."""
def __init__(self, embedder: Embeddings, observation_prefix: str = "embeddings"):
self._embedder = embedder
self._observation_prefix = observation_prefix
def __getattr__(self, name: str):
"""Proxy all other attributes to the underlying embedder."""
return getattr(self._embedder, name)
@observe(as_type="embedding")
def embed_documents(self, texts: list[str]) -> list[list[float]]:
self._rename_current_span("embed_documents")
self._update_observation_metadata(texts)
return self._embedder.embed_documents(texts)
@observe(as_type="embedding")
def embed_query(self, text: str) -> list[float]:
self._rename_current_span("embed_query")
self._update_observation_metadata([text])
return self._embedder.embed_query(text)
@observe(as_type="embedding")
async def aembed_documents(self, texts: list[str]) -> list[list[float]]:
self._rename_current_span("aembed_documents")
self._update_observation_metadata(texts)
if hasattr(self._embedder, "aembed_documents"):
return await self._embedder.aembed_documents(texts)
return await run_in_executor(None, self._embedder.embed_documents, texts)
@observe(as_type="embedding")
async def aembed_query(self, text: str) -> list[float]:
self._rename_current_span("aembed_query")
self._update_observation_metadata([text])
if hasattr(self._embedder, "aembed_query"):
return await self._embedder.aembed_query(text)
return await run_in_executor(None, self._embedder.embed_query, text)
def _rename_current_span(self, suffix: str) -> None:
"""Give the span a descriptive name like 'azure_openai.embed_documents'."""
try:
langfuse_client.update_current_span(
name=f"{self._observation_prefix}.{suffix}",
)
except Exception:
pass
def _update_observation_metadata(self, texts: list[str]) -> None:
"""Attach model name and estimated token usage to the span."""
model_name = self._resolve_model_identifier()
token_count = self._estimate_total_input_tokens(texts)
if model_name is None and token_count is None:
return
get_span = getattr(langfuse_client, "_get_current_otel_span", None)
if not callable(get_span):
return
current_span = get_span()
if current_span is None:
return
usage_details = {"input_tokens": token_count} if token_count else None
try:
LangfuseEmbedding(
otel_span=current_span,
langfuse_client=langfuse_client,
).update(
model=model_name,
usage_details=usage_details,
)
except Exception:
pass
def _resolve_model_identifier(self) -> Optional[str]:
"""Extract model name from various provider-specific attributes."""
for attr in ("model", "model_id", "deployment", "azure_deployment", "model_name"):
value = getattr(self._embedder, attr, None)
if isinstance(value, str) and value:
return value
return None
def _estimate_total_input_tokens(self, texts: list[str]) -> int:
"""Estimate token count using ~4 bytes per token heuristic."""
total = 0
for text in texts or []:
if text:
total += max(1, math.ceil(len(text.encode("utf-8")) / 4))
return totalUsage
Wrap your embedder once during initialization:
from langchain_openai import AzureOpenAIEmbeddings
# Create your embedder as usual
embedder = AzureOpenAIEmbeddings(
azure_deployment="text-embedding-3-small",
# ... other
)
# Wrap it for tracing
traced_embedder = LangfuseObservedEmbeddings(embedder, "azure_openai")
# Use traced_embedder everywhere in your app
vectors = traced_embedder.embed_documents(["Hello", "World"])To prevent accidental double-wrapping:
def wrap_embedder_with_observe(embedder: Embeddings, provider_name: str) -> Embeddings:
if isinstance(embedder, LangfuseObservedEmbeddings):
return embedder
return LangfuseObservedEmbeddings(embedder, provider_name)What You Get
Each embedding call now appears in Langfuse with:
- Span name: e.g.,
azure_openai.embed_documents - Model identifier: Automatically extracted from the embedder
- Token usage: Estimated input tokens (useful for cost tracking)
- Timing: Start/end timestamps for performance analysis
Notes
- The token estimation uses a simple heuristic (~4 bytes per token). For precise counts, you could integrate a tokenizer like
tiktoken, but the estimate is usually good enough for monitoring. - The
__getattr__proxy ensures the wrapper is fully transparent - any attributes or methods on the underlying embedder remain accessible. - The async methods fall back to running the sync version in an executor if the underlying embedder doesn’t support async natively.
Comments